
AkaiEgoStack: The Data Capture Rig
Bringing Scaling laws for humanoids
– Research @Akai Space Labs
The Landscape: Data as the New Bottleneck
In our first post, we laid out the high-level thesis for AkaiEgoStack: scaling laws for physical AI require an end-to-end data engine, not just better robot bodies. That episode focused on the necessity of VLA models as the current standard for robot policy learning.
Today, the architectural landscape is shifting. While VLA models remain dominant for their autoregressive simplicity, we are seeing the rise of JEPA as a major contrastive competitor. Regardless of which architecture you are building on, the fundamental requirement is unchanged: the success of the model is directly tied to the temporal and spatial fidelity of its training data.
The Device Gap
Existing hardware consistently fails the egocentric data engine requirement. After evaluating the full landscape of options, three structural traps emerge:
- Smartphones: The ergonomic profile is unsuitable for high-volume data acquisition. Furthermore, the unit economics are unsustainable when attempting to embed the precision sensor architecture required for reliable pose estimation.
- AR Glasses: Commercial availability remains a bottleneck, and existing platforms are too restrictive for specialized research. Current industry leaders, such as Meta's Aria, utilize opaque software stacks that act as proprietary black boxes.
- Existing Custom Solutions: Our industry evaluations reveal that most bespoke hardware fails the fidelity test. These devices generally lack the requisite sensor depth and spatial accuracy needed to generate high-quality, actionable training datasets.
The only viable path forward is a bespoke device, engineered with the correct sensor stack, optimised for form factor, and designed around a precise data contract.
Our Philosophy: Designing for Scale and Fidelity
Our efforts are towards building a fleet-ready data engine designed for scale, not just a toy that sits in the lab. The architecture is guided by three non-negotiable principles:
- Hardware-Level Synchronisation: Action models operate on causality. If visual and inertial streams drift, the model learns noise instead of physics. We enforce synchronisation at the hardware level, by design, ensuring every frame is anchored to its exact inertial state. This is the non-negotiable prerequisite for training performant VLA and action policies.
- High-Fidelity Proprioception: To master dexterous manipulation, a model must understand the observer's reference frame and the hand as a precision instrument. We prioritise a sensor stack capable of capturing high-fidelity headpose, wrist 6DoF poses, and fine-grained finger articulation. This provides the proprioceptive ground truth required for models to map visual intent to physical manipulation.
- Ergonomic Scalability: Data collection only scales through sustained, high-volume operation. We are optimising for a lightweight, non-intrusive form factor that allows operators to perform real-world tasks without fatigue. By designing for cost-efficient mass manufacturing from the outset, we move beyond bespoke lab equipment toward a deployable fleet of high-fidelity collectors.

Figure
Prototype Akai EgoStack rig worn in the field - lightweight, head-mounted capture for sustained data collection.
Akai Egocentric Capture Device - Technical Brief
Our capture device is built around a single architectural mandate: hard-real-time synchronisation. Every component is strictly orchestrated to deliver the temporal ground truth required for action model training.

Figure
Prototype Akai EgoStack rig. Stereo cameras mounted on a head-worn frame
Core Components
All components are co-designed for the synchronisation contract described below.
| Component | Role | Key Spec | Engineering Rationale |
|---|---|---|---|
| Raspberry Pi 5 | Compute Hub | 4 GB RAM | High-throughput video encode + data logging; very good for initial experimentation |
| Onsemi AR0234CS Stereo Cameras (×2) | - | Global shutter, 1/2.6″ CMOS | Eliminates rolling-shutter artifacts; stereo pair provides depth |
| STM32G474 | Time Conductor | ARM Cortex-M4, 170 MHz | Offloads timing from Pi; deterministic 30 Hz trigger with μs precision |
| TDK ICM-20948 | IMU (9DoF) | 3-axis accel + gyro + mag | FSYNC pin locks inertial samples to camera exposure edge |
Table
Component specification summary.
Synchronisation Architecture
Hardware-level synchronisation is more than wiring components together; it is a complex, co-designed engineering challenge. While a centralised hardware pulse provides the electrical backbone, true precision comes from the custom firmware and software stack we developed to orchestrate the capture phases.
Our proprietary stack handles precise trigger ramping, timing alignment, and complex timestamp locking. This deep integration between custom firmware on the STM32 and high-level capture software on the Pi eliminates the timing drift inherent in consumer devices, providing the robust unified temporal foundation required for training action-oriented models.
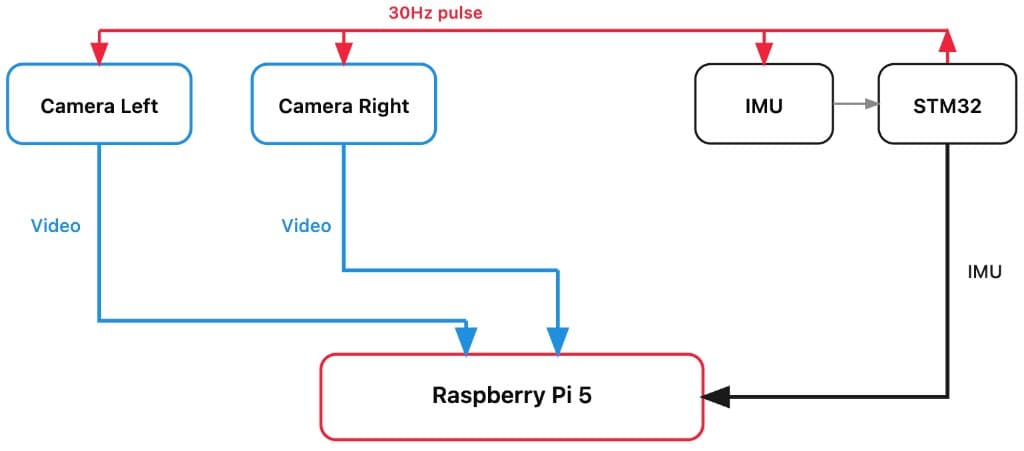
Figure
Synchronisation architecture. The STM32 Time Conductor issues a 30 Hz hardware pulse to both cameras and the IMU simultaneously. All video and inertial data streams converge on the Raspberry Pi 5.
Scrub through a hardware-synced capture session below - stereo frames and IMU streams locked to the same MCU trigger timeline.
Looking Ahead: Mass Manufacturing and Ergonomics
The prototype device is the proof of the capture contract, not the end-state product. The architecture is validated and moving forward, our engineering effort splits into two primary paths to make it fleet-ready.
Path 1 - Ergonomics & Form Factor
The rig must be lightweight, unobtrusive, and comfortable enough for multi-hour data collection sessions. This requires migrating from development boards to custom PCB hardware. Our current target is a total rig weight comparable to a hat, with a profile that does not constrain head movement or field of view.
Path 2 - Cost-Efficient Fleet Manufacturing
Fleet-scale deployment demands designing for cost-efficiency. We are rationalising our sensor stack and component selection for mass manufacturing at an optimised BOM. This is the threshold at which deploying hundreds of rigs simultaneously becomes operationally viable.
Key Terms & Acronyms
- VLA
- Vision-Language-Action model. A neural architecture that jointly processes visual input, language instructions, and physical actions. Currently the dominant paradigm for robot policy learning.
- JEPA
- Joint-Embedding Predictive Architecture. A self-supervised framework that predicts abstract representations rather than raw pixels. An emerging contrastive competitor to VLA.
- IMU
- Inertial Measurement Unit. A sensor combining accelerometers and gyroscopes to measure 3D motion.
- 6DoF
- Six Degrees of Freedom: translation along X/Y/Z axes and rotation (roll, pitch, yaw).
Stay tuned for further updates!
