AkaiEgoStack : Bringing Scaling laws for humanoids
Ep.1. Building an Egocentric Data Engine for Humanoid Robots
– Research @Akai Space Labs
1. Bottleneck and opportunity in current robotics infrastructure
Humanoid robotics is entering its scaling-law phase, but the infrastructure around it has not caught up.
In language and vision, progress accelerated once the field found repeatable ways to scale data. Robotics does not have that loop yet. We have better model architectures, better robot bodies, and better demos every year, but the data layer is still fragmented, expensive, and mostly trapped inside individual labs and companies.
That is the bottleneck. VLA models do not just need more videos of the world. They need embodied data from the right point of view: what the human saw, how the head moved, where the hands were, what action happened next, and how that action changed the scene.

But the current ways of collecting this data do not scale cleanly. Teleoperation is high-quality but slow and platform-specific. Simulation is useful, but brittle for messy contact-rich work. Internet video is abundant, but missing the action channel. Most AR glasses and camera rigs were not designed as commercial VLA data infrastructure.
This is the important signal from NVIDIA's EgoScale work: head-mounted egocentric data, captured at scale from humans doing everyday manipulation, can become useful pretraining data for robot policies. The camera pose is close to the future robot's point of view, the hands are visible during real work, and the data distribution is much closer to deployment than scripted lab teleoperation.
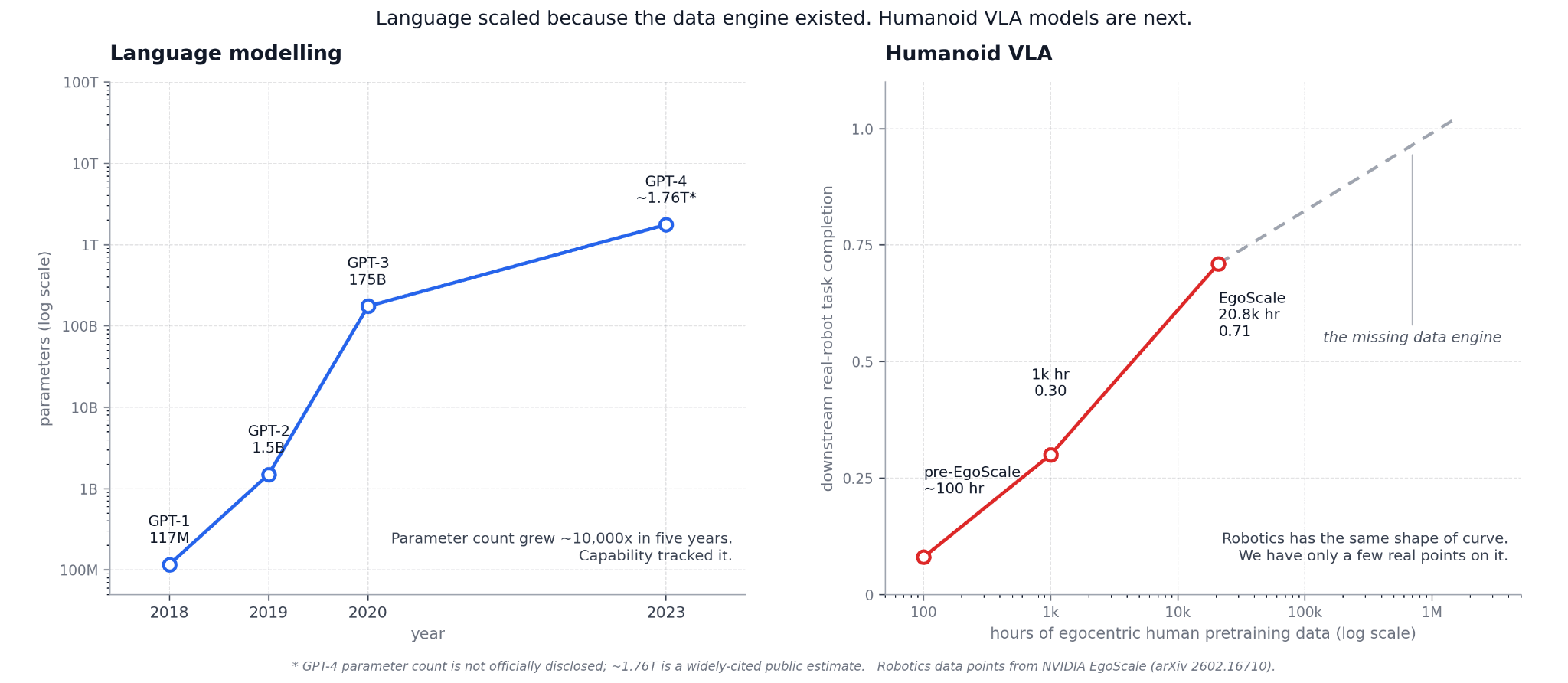
The opportunity lies in building the data engine that lets humanoids benefit from scaling laws. This post lays out the high-level thesis, the four parts of the stack, and where we are starting.
2. The Four Layers
We think anyone serious about scaling data for physical AI has to master four things:
- The data capture device. The physical capture rig. Sensor selection, synchronisation, ergonomics, ruggedisation, ops-friendliness.
- Operations for scaling data. Recruiting and instrumenting workers across real workplaces, handling consent, privacy, redaction, on-shift troubleshooting, data transfer logistics.
- The egocentric data pipeline. Taking raw recordings and turning them into trainable episodes: stereo VIO, hand-pose extraction, action-proxy lifting, sync validation, dataset versioning.
- Research on training with that pipeline. Using data collected through the device, operations, and egocentric data pipeline to validate scaling behavior in our own lab: which data improves VLA performance, how performance changes with scale, and which parts of the stack create the most leverage.
3. The landscape today
The market is not empty. Different projects have already proved different parts of the stack.
EgoScale (NVIDIA Research) is the strongest signal on the training side. It showed that head-mounted egocentric data, captured at scale from humans doing real manipulation, can become useful pretraining data for robot policies.




Project Aria (Meta) is the strongest signal on the hardware and sensing side. It proves that a small head-worn device can run tightly synchronised cameras, IMU, and VIO in a real form factor, but it is still a research platform, not a commercial robotics data-scaling device.

Other work usually falls into two buckets. Some teams build their own devices, but the sensors are often not strong enough for high-quality pose and action data. Others use high-end phones, which can work for early experiments but create poor worker UX and become expensive at thousands of field deployments.
While individual projects have advanced one layer at a time, what we do not yet see is a company that has cracked devices, operations, egocentric data pipeline, and training research together.
4. The AkaiEgo stack
We are building the AkaiEgo stack, covering the 4 layers previously discussed — device, ops, egocentric data pipeline, and training research connected into one feedback loop.
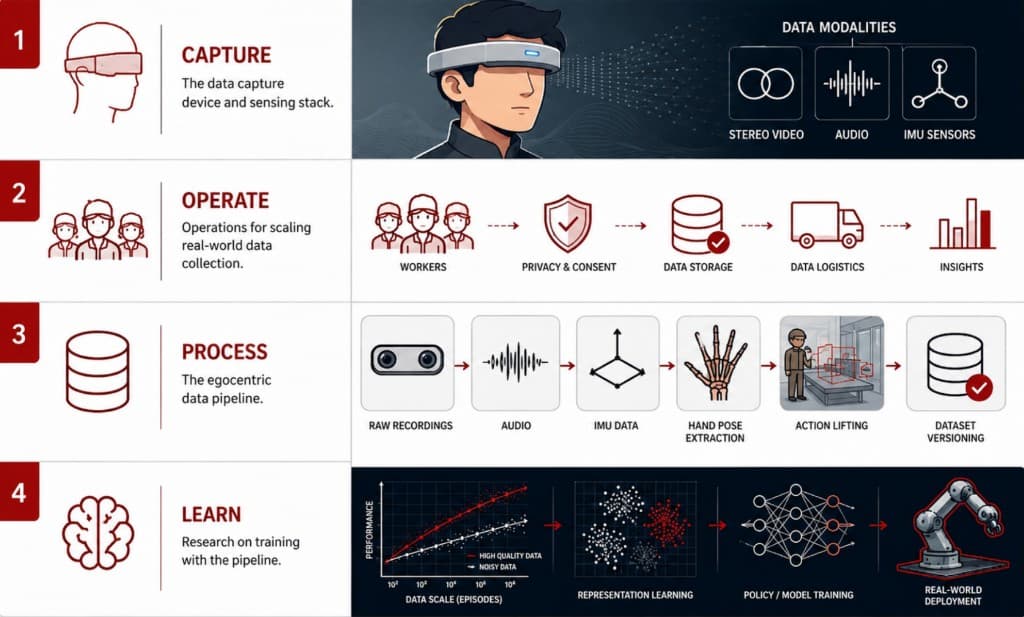
I. Device
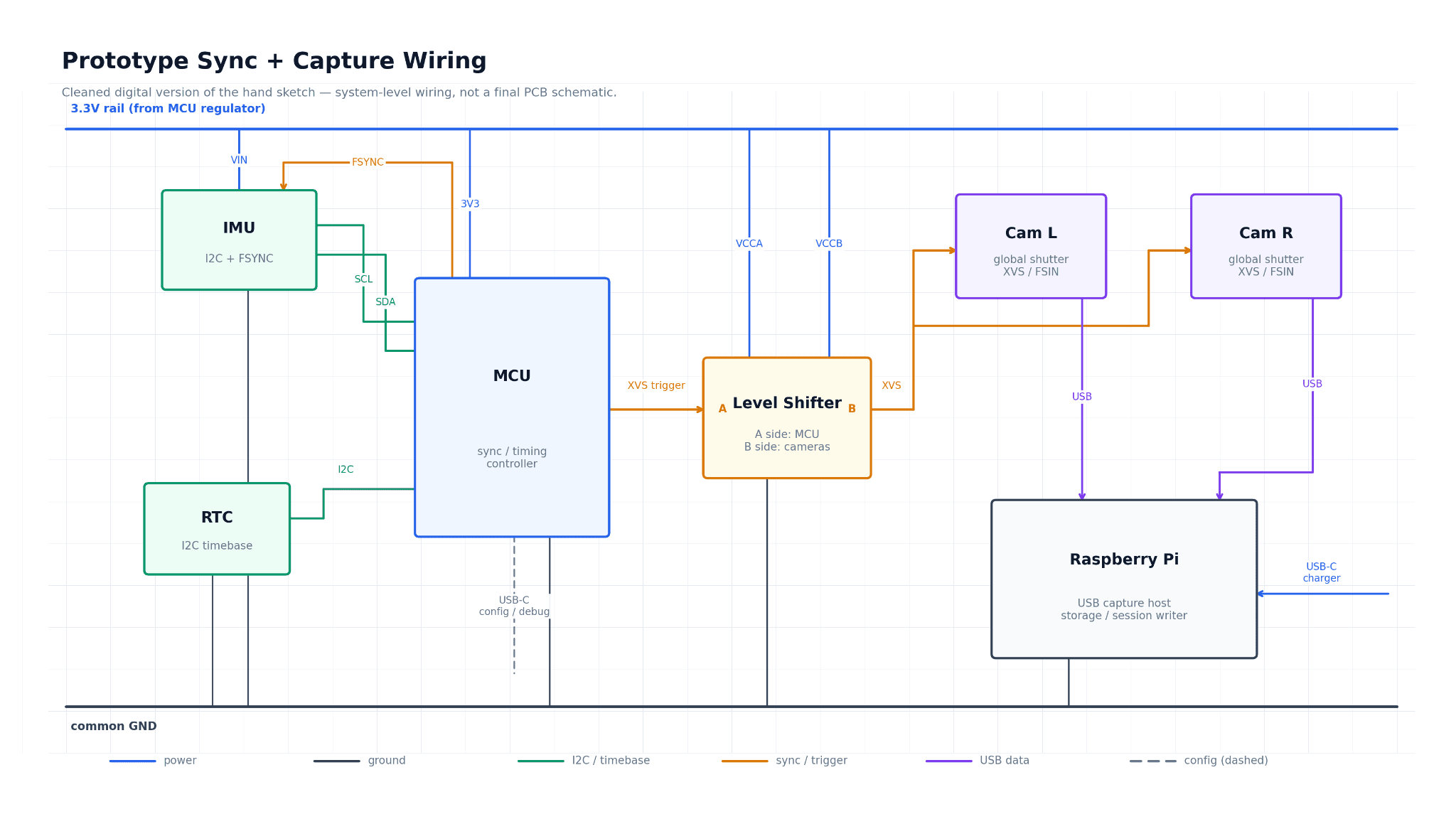
We have moved from research into prototyping a dedicated egocentric capture device. The capture layer has to be comfortable enough for full-shift human work, good unit economics to deploy at scale, and precise enough to capture useful action traces for VLA training. The current direction is a head-worn rig with stereo cameras, IMU, and hardware-level time alignment. The exact hardware decisions deserve their own essay, because each choice has tradeoffs: global shutter vs rolling shutter, stereo vs phone depth, compute architecture, and how much sync precision is actually needed for downstream action recovery.
II. Operations
We have seen various companies running egocentric data collection efforts, including phone-based capture. The learnings: data collection is not just a camera/sensor problem — worker comfort, setup time, device cost, consent, battery, storage, and site-to-site repeatability all decide whether the system can scale. Having access to and collaborating with people who already employ large numbers of workers is just as important. They matter because scaled data collection depends on not just hardware but trusted access to real messy workplaces, which we have cracked by showing how industry grounded analysis on the workers' egocentric data can bring clear ROIs for the end collectors or organisation partner.
III. Egocentric data pipeline
This layer turns raw sessions into calibrated video, aligned sensor streams, pose recovery, action proxies, privacy redaction, QC gates, and dataset licensing and versioning. Without it, more captured hours do not automatically become better training data. We have started prototyping the pipeline around the data contract: what gets recorded, how it is stored, how timestamps are represented, what quality checks run first, and what a trainable episode should look like.
IV. Training
The goal of the training research is to validate the scaling law in our own lab, using data collected by our own device, through our own operations, and processed by our own egocentric data pipeline. This is where the stack closes the loop: we measure which data improves VLA performance, how performance changes with scale, which sensors matter, and what parts of the system can be simplified without hurting the model.
5. What we will publish next
This essay was about the roadmap to bring scaling laws for humanoids. The next posts will be more specific around —
- Deep dive into the device. Why we are building a dedicated egocentric rig, what sensor stack we chose for the prototype, why hardware sync matters, what we rejected, and how we think about cost at deployment scale.
- Scaling operations. What we learned from data collection work, why worker UX matters, why phones are a useful prototype but weak scaling device, and what a repeatable field workflow needs to look like.
- The egocentric data pipeline. The path from raw egocentric sessions to structured training data, including timestamping, quality checks, pose recovery, privacy redaction, and dataset versioning.
- Close loop training research. We want to answer the questions that actually matter: does data collected through our own device and operations improve robot policies, where do scaling laws show up, and which parts of the stack create the most leverage?
We are going to publish this as we build it. The goal is not to pretend the stack is complete, but to make the work legible while we move from research insight to infrastructure.
References
- Kaplan et al., Scaling Laws for Neural Language Models, 2020. https://arxiv.org/abs/2001.08361
- Hoffmann et al., Training Compute-Optimal Large Language Models (Chinchilla), 2022. https://arxiv.org/abs/2203.15556
- NVIDIA, EgoScale, 2026. https://arxiv.org/abs/2602.16710
- Meta, Project Aria, 2023. https://www.projectaria.com/
- Grauman et al., Ego4D: Around the World in 3,000 Hours of Egocentric Video, CVPR 2022. https://ego4d-data.org/
- Padalkar et al., Open X-Embodiment: Robotic Learning Datasets and RT-X Models, 2023. https://arxiv.org/abs/2310.08864
